Mutexs, Semaphores, Condition Variables, Critical Sections… There are so many different synchronisation types to choose from but how do they compare in terms of performance and what other synchronisation types are there we can explore?
My tests here have been written with a job-system in mind, where worker threads are waiting for work which is triggered by another thread. So I aim to understand the performance overhead involved in triggering the synchronisation types but also the time on the worker threads to be woken up as a result. I will also explore how this scales with multiple threads and some alternatives to synchrionsation types such as spins and sleeps. I’m keen to understand what synchronisation types scale best and what will allow us to wake our threads as fast as possible.
Synchronisation Methods
In my tests I’ll be exploring the following methods for synchronising, most of which are Win32 types unless otherwise specified. All of the types below ultimately end up invoking as syscall when triggering and waiting which allows the kernel to stop the thread from running.
- Semaphore
- Event (Single Event)
- Event (Separate Event object per-thread)
- Critical Section (With volatile bool to trigger)
- Critical Section And Spin Count (With volatile bool to trigger)
- Condition Variable (With Critical Section)
- Condition Variable (With Critical Section And Spin Count)
- Synchronization Barrier
- Condition Variable (With SRW Lock – Slim Read/Write Lock)
- WaitOnAddress (Single address)
- WaitOnAddress (Separate address per-thread)
- std::mutex (Internally this uses a SRW Lock)
- std::condition_variable & std::mutex (Internally this uses a SRW Lock)
- Mutex (With volatile bool to trigger)
- std::atomic_flag Wait
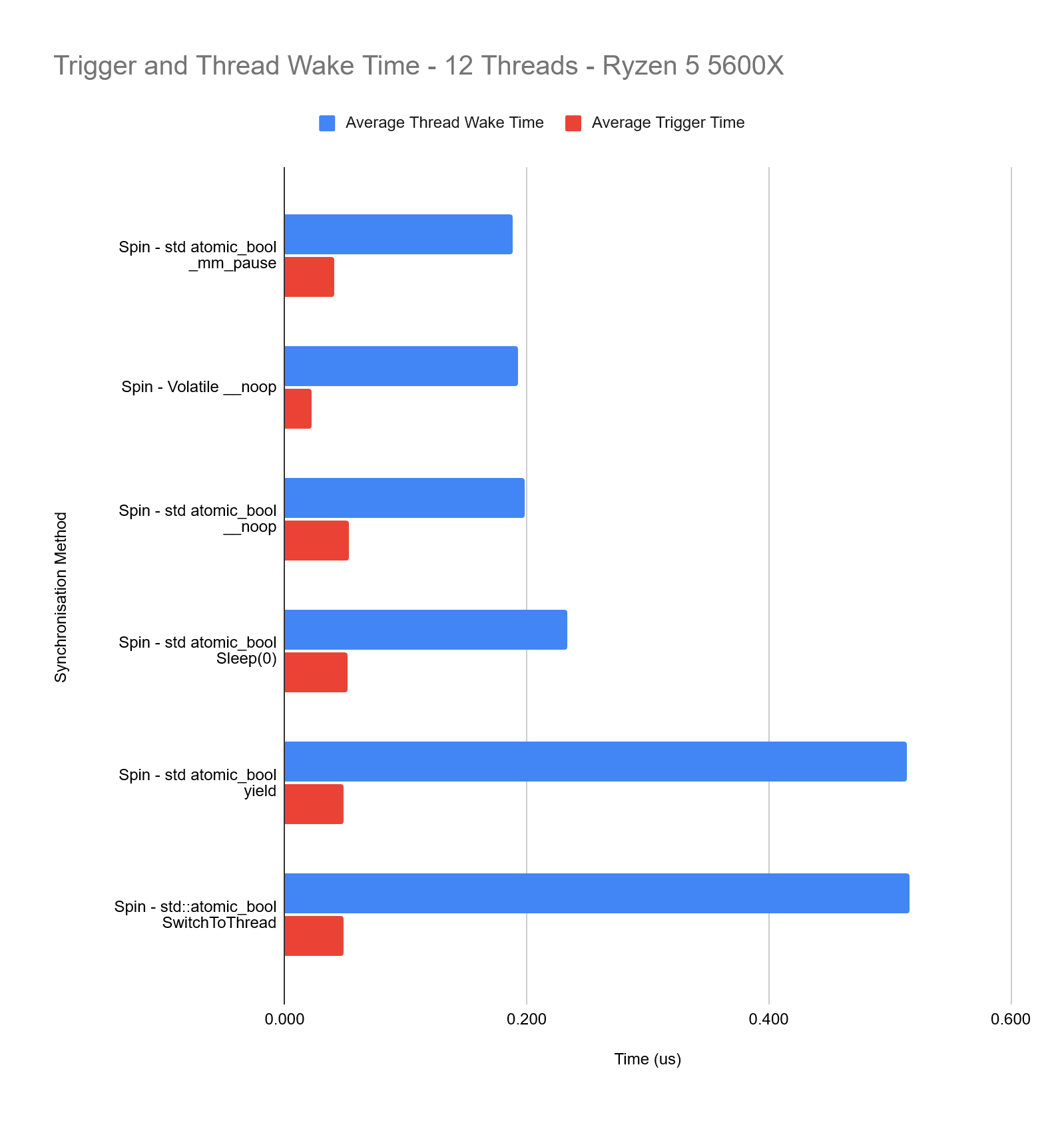
We will also explore synchronising threads using a while loop to spin and checking for a specified value. In the body of the loop we test with different operations such as yielding and sleeping.
- Spining Methods
- Spin: volatile bool +
__noop() - Spin: std::atomic_bool +
__noop() - Spin: std::atomic_bool +
_mm_pause() - Spin: std::atomic_bool +
std::this_thread::yield() - Spin: std::atomic_bool +
SwitchToThread() - Spin: std::atomic_bool +
Sleep(0)
- Spin: volatile bool +
Test Setup
The tests work by spawning x number of threads and causing all threads to wait with a specific sync type. Majority of the results I’ll be sharing here are using the total number of threads returned by std::thread::hardware_concurrency minus one (for the main thread which will be triggering).
Once each thread is waiting, the main thread will then trigger all threads at once. We measure how long the main thread takes to trigger and then how long it takes from the trigger for the threads to start executing. For these tests on Windows I’m using QueryPerformanceCounter because it is accurate and allows good comparison of timings between different threads.
For the initial test, we are running with the default thread priority (THREAD_PRIORITY_NORMAL) and the default thread affinity (The thread can run on any logical processor).
Results
The results below are from a AMD Ryzen 5 5600X (6 cores, 12 logical processors) running Windows 11 version 25H2 with 11 worker threads and 1 main trigger thread. Results have been averaged over 32,000 runs per sync type.
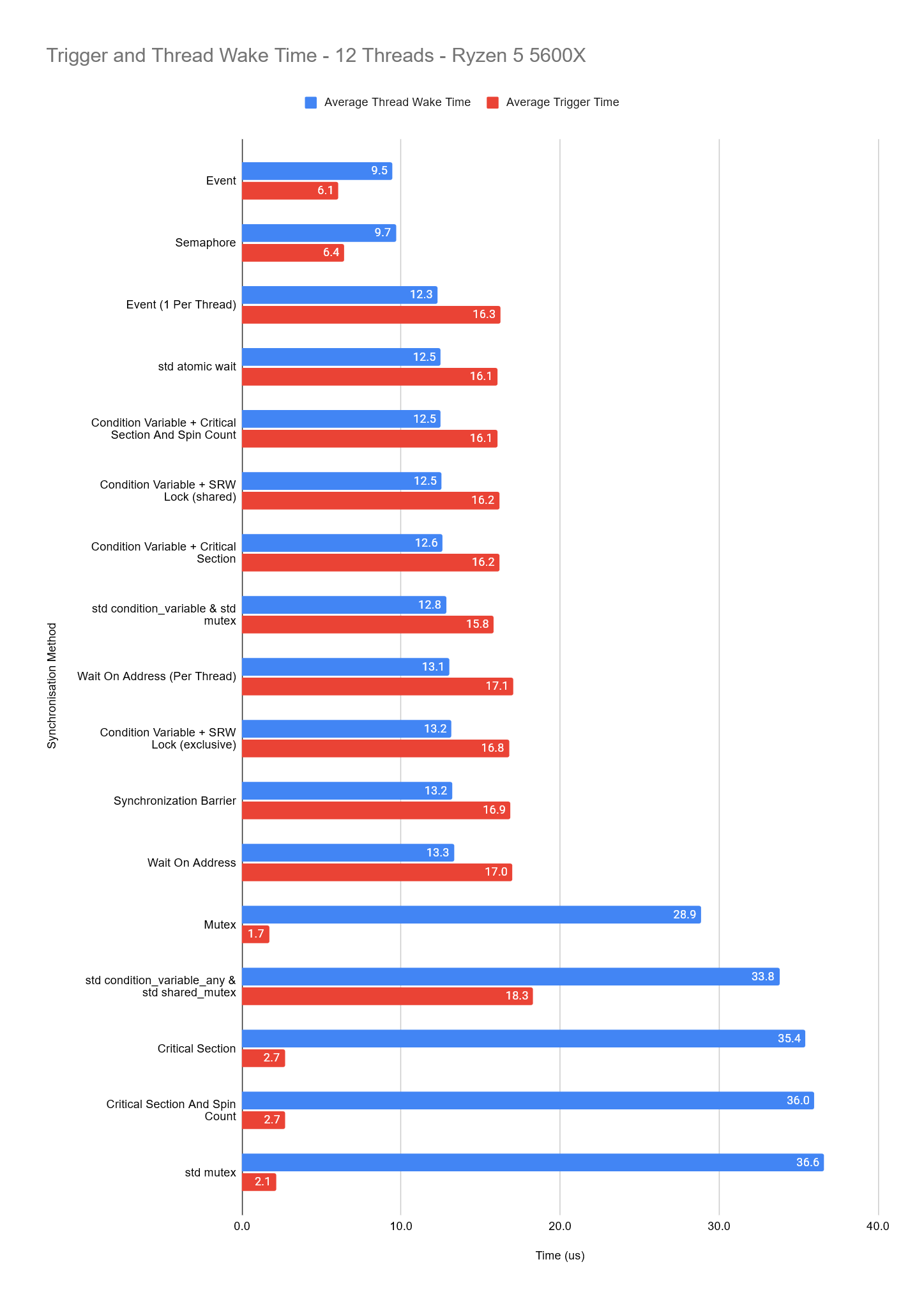
We record the time the main thread takes to invoke the trigger and then how long from the trigger occurring, each thread takes to wake.
The immediate standout is the spinning methods being the fastest, this doesn’t come as a surprise though because the threads have never been put in a waiting state, they are just spinning and wasting CPU time and power.
So if we now turn our attention to the full synchronisation types, we can see two distinct groups of results focusing on the thread wake time, with the latter being the Mutex & Critical Sections being used without a condition variable.
Changing Thread Count
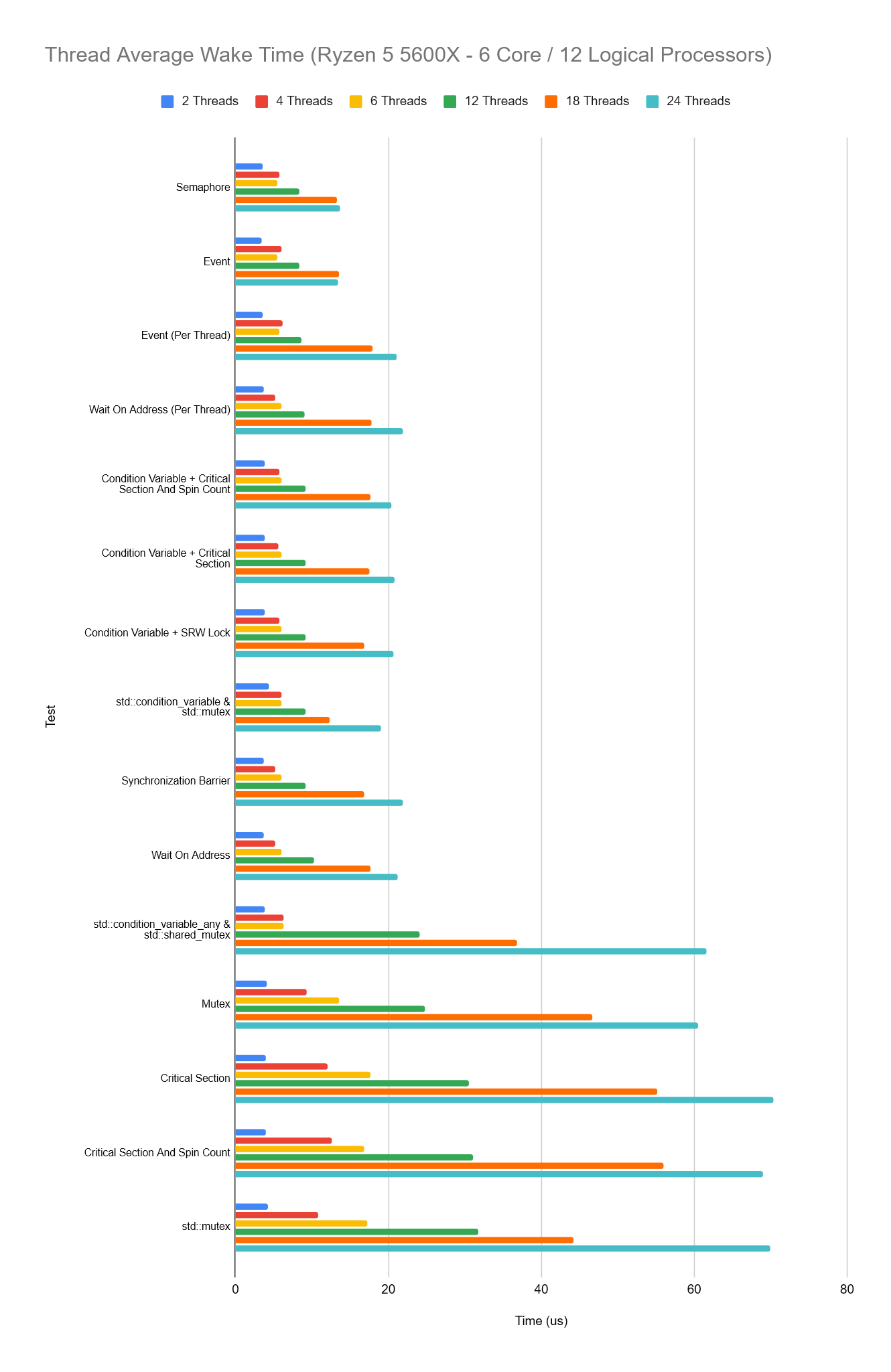
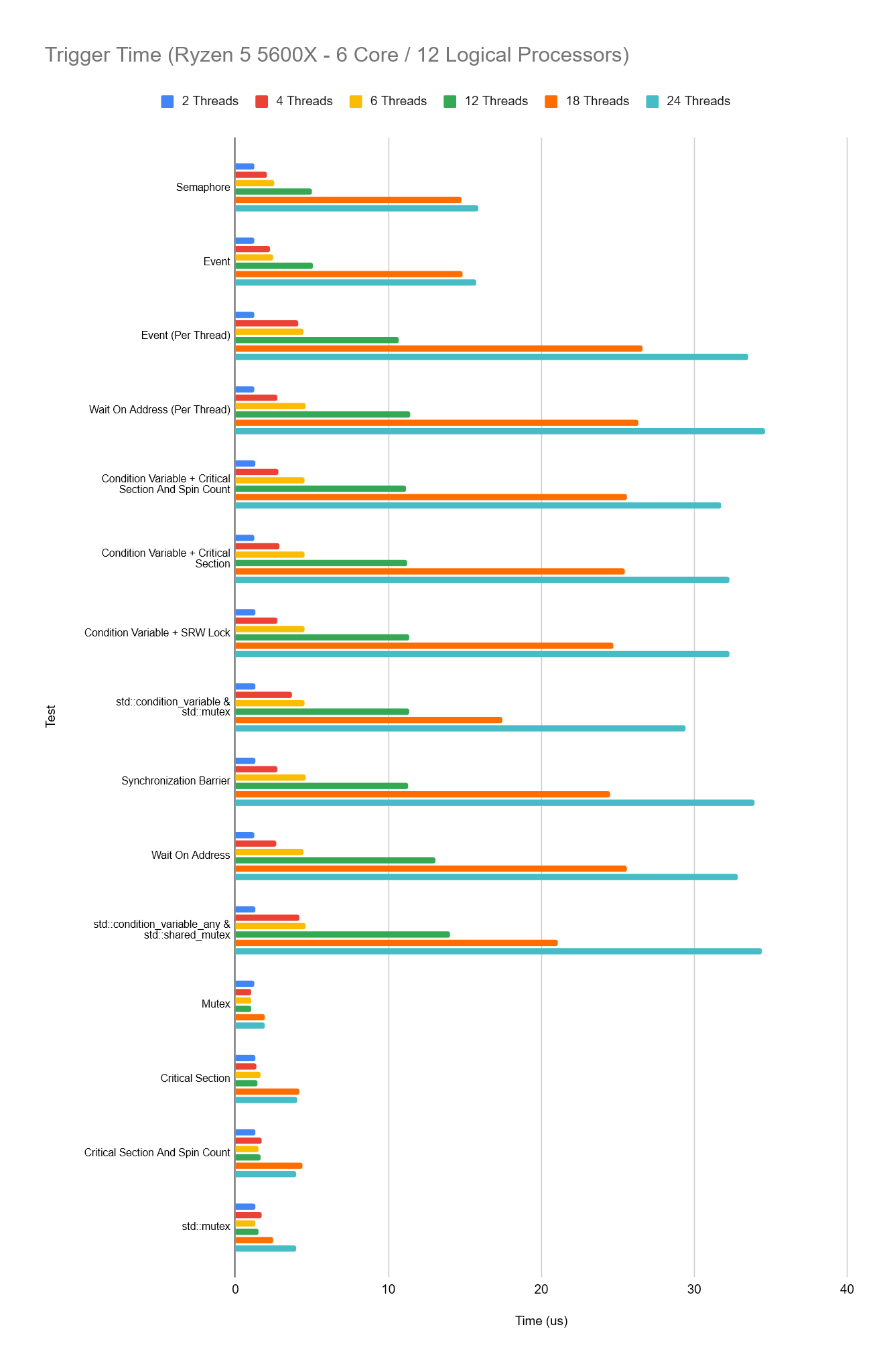
So how does the performance change in our setup when we change the number of threads which are woken? We will again compare the time the thread takes to wake and also the trigger time. As before, thread counts below include the main triggering thread.
The pattern we see across all sync types is that as the thread count increases, so does the average wake time for each thread and for the slower sync setups we’ve got, this increase is much larger.
It’s also interesting to observe that when we’re waking just a single thread however, performance is very similar across all sync types.
Variations
Thread Priority:
In order to give all of our threads the best chance of being executed, we call SetThreadPriority with THREAD_PRIORITY_HIGHEST.
The results are perhaps not as you would expect, by setting all threads to be the highest priority, we a consistent drop in performance as every type tested takes longer to wake compared to the default thread priority!
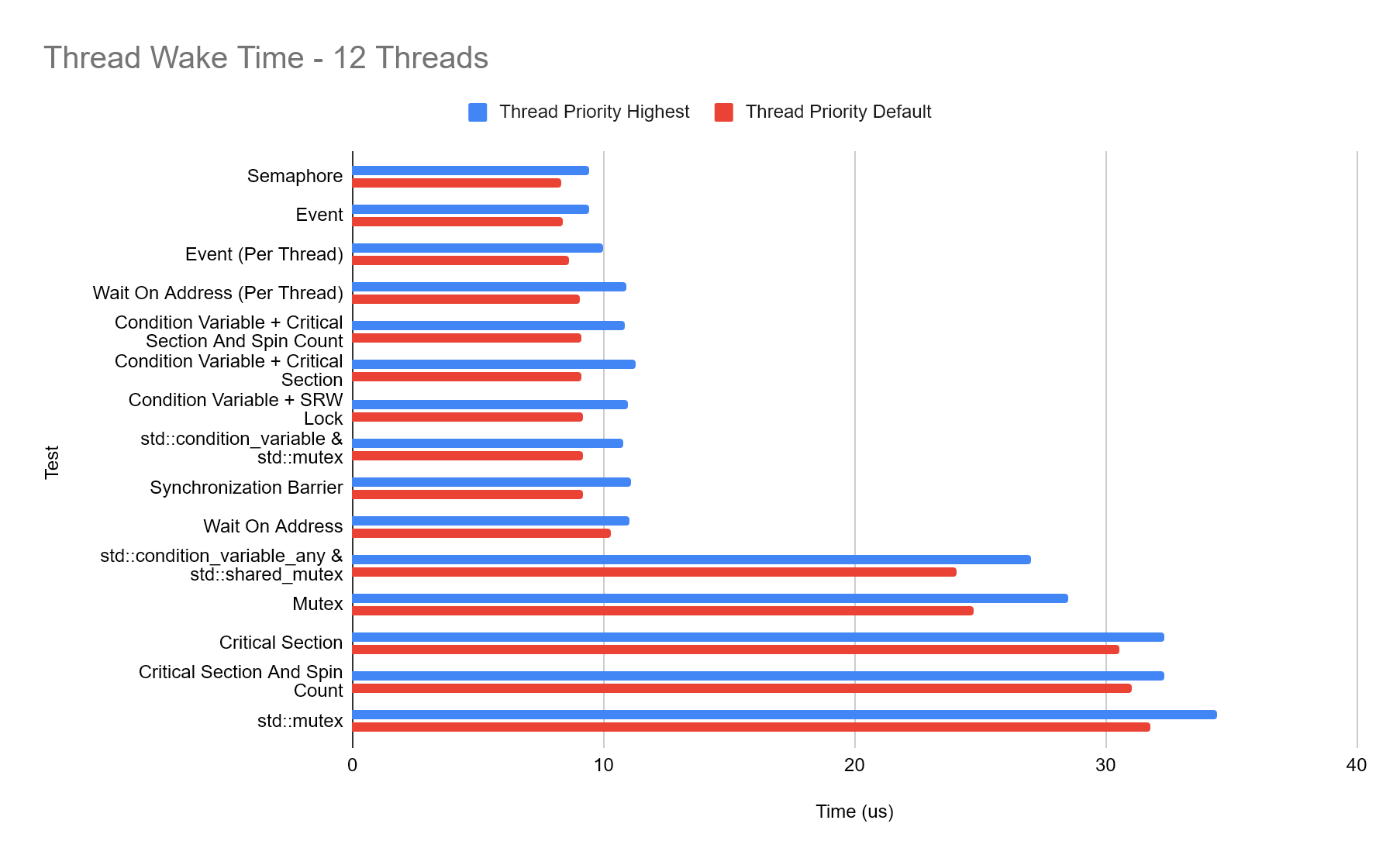
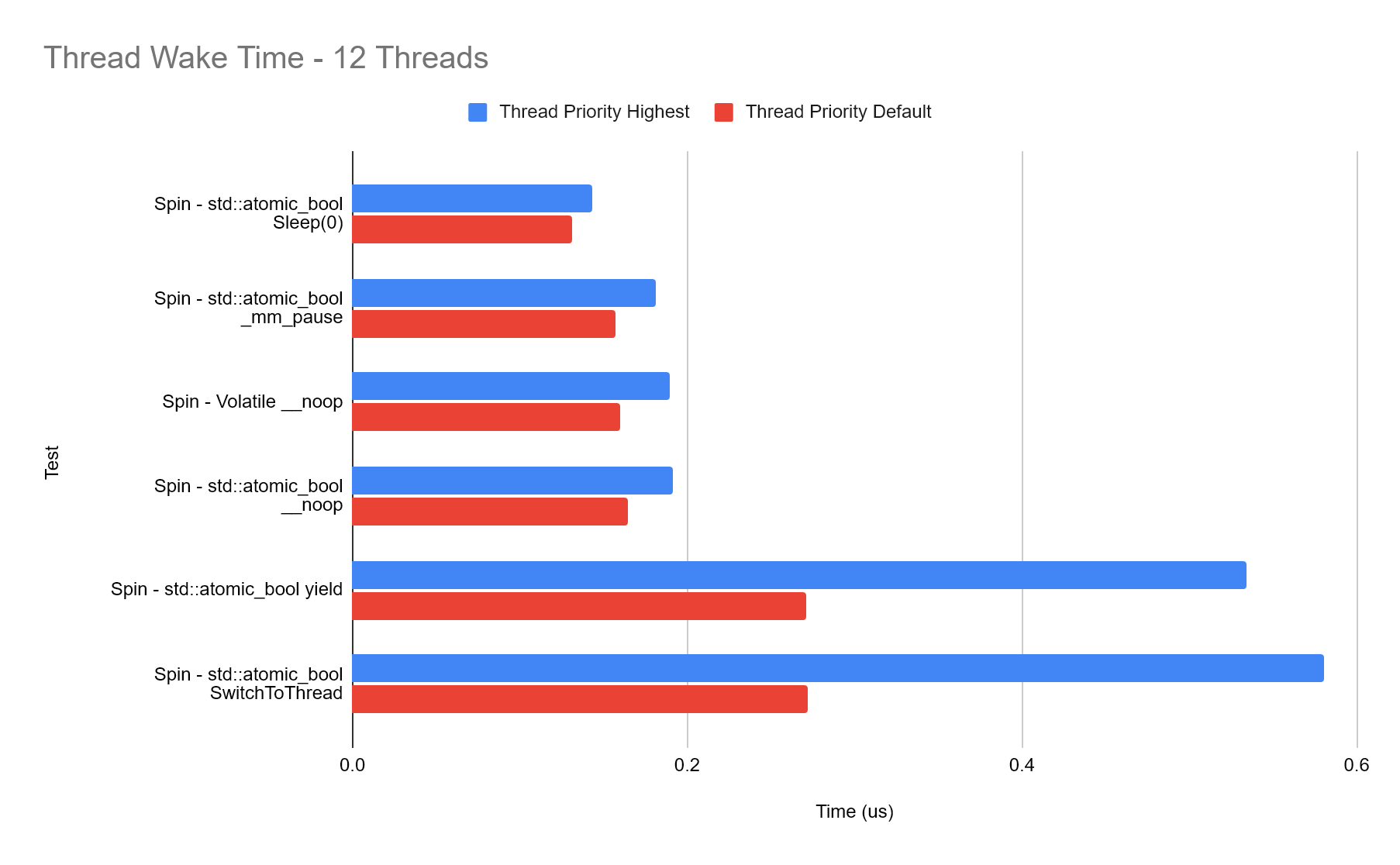
Thread Affinity:
For these tests, we lock each thread to a unique logical processor with SetThreadAffinityMask. This means threads wont context switch around different threads. For video game development on consoles, it’s quite common for us to lock threads to specific logical processors/cores because we know the exact hardware our code will be running on. Naturally, this is much more difficult on PC because hardware can differ so much, as can the number of cores and logical processors so despite the results below, I would always exercise caution before shipping code with thread affinities locked.
The results below are mixed. In many cases performance is very similar and worst case, we’re negatively affecting performance. I think on a PC system where you’re running many different processes and your application won’t have exclusive access to specific cores, it’s probably best to let the OS handle thread scheduling…
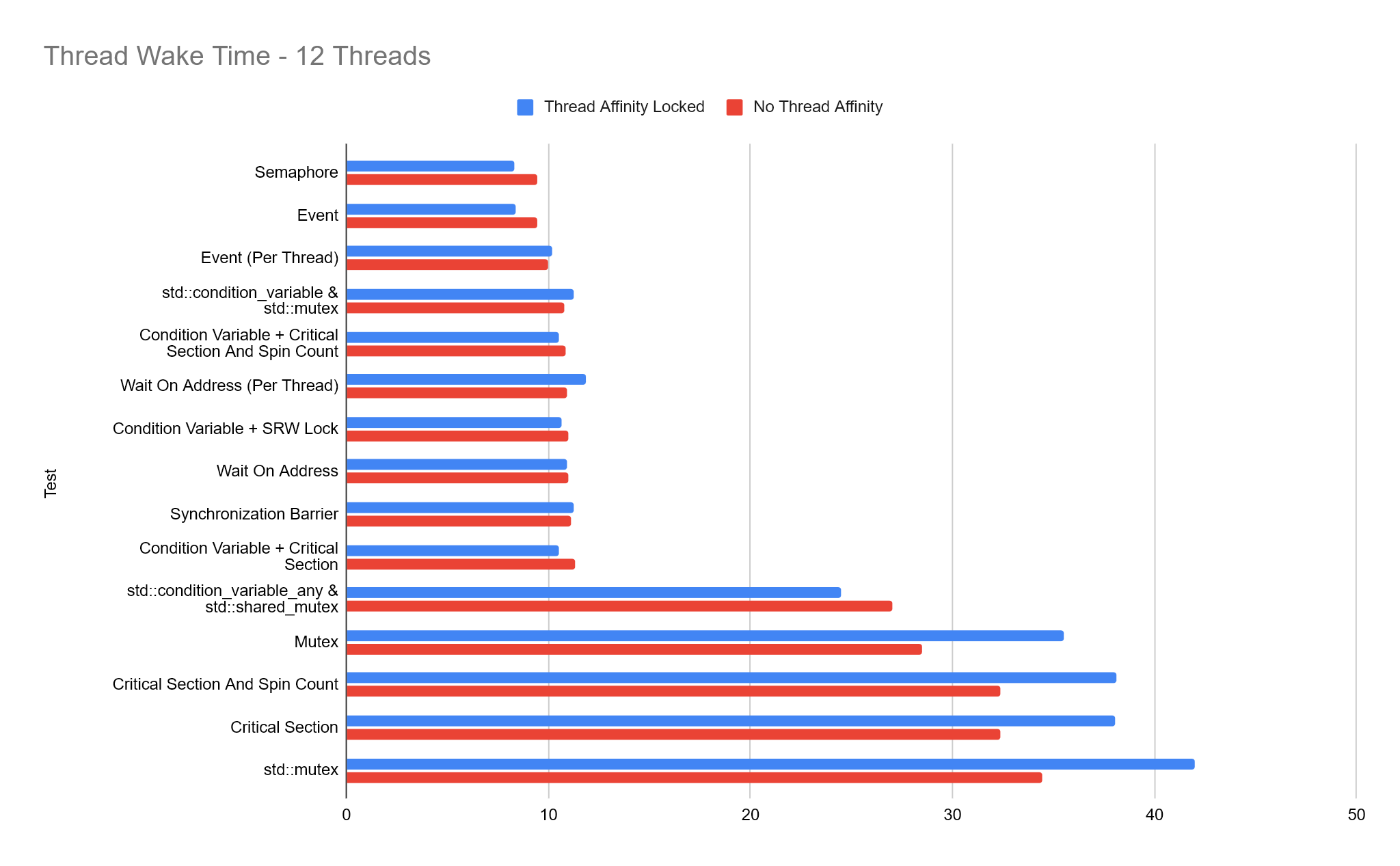
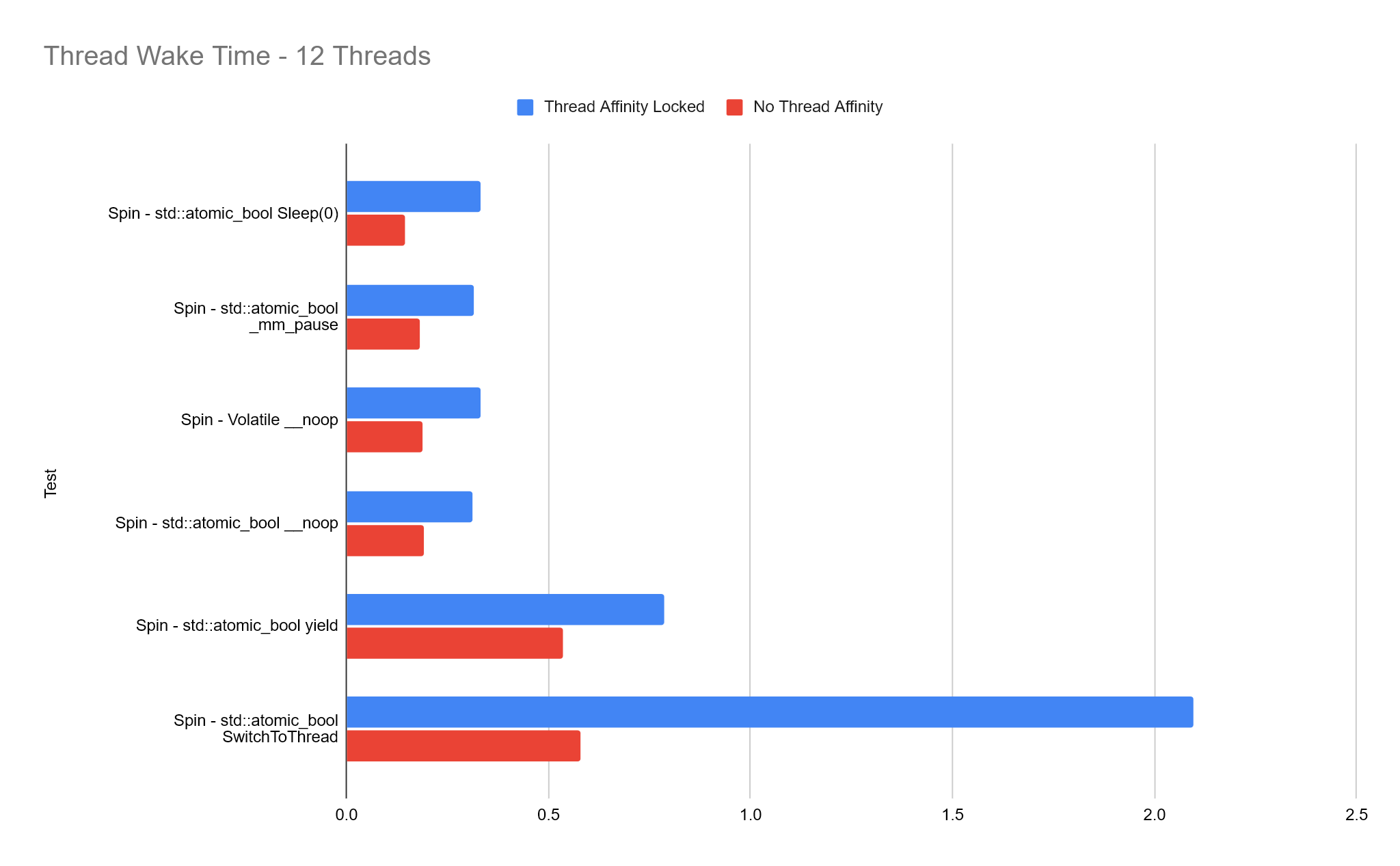
Comparing Each Thread
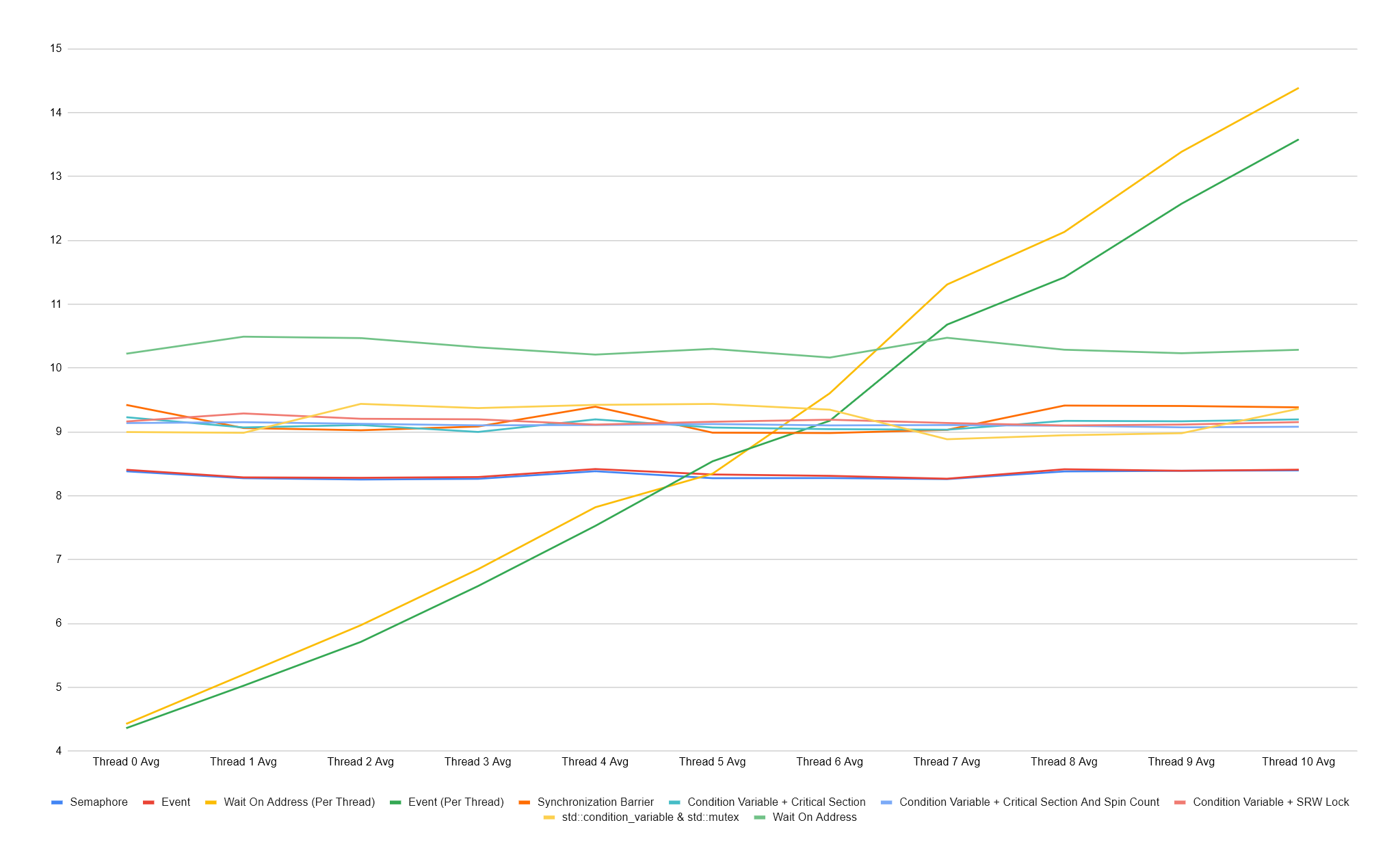
I found it important, given some of the tests above include a synchronisation object per-thread, to also record the time each thread took to wake to see if we can spot any patterns. Below the chart shows that the Event (Per Thread) and Wait On Address (Per Thread) wake the first thread they trigger before the last thread they trigger, which makes complete sense, but I think it’s important to look at it this way instead of just the average because while we’re waking early threads faster, later ones are slower than the average. We’re seeing this pattern because we’re in control of the thread waking order, there will be an order of each waked thread for the other sync types, but it’s just not consistent each time.
In order to visualise the difference in waking order between the first and last threads, I collect and sort the wake time for each thread and keep the average wake time for the order each thread was woken. Doing this, we get charts showing the average wake time in order for our sync types:
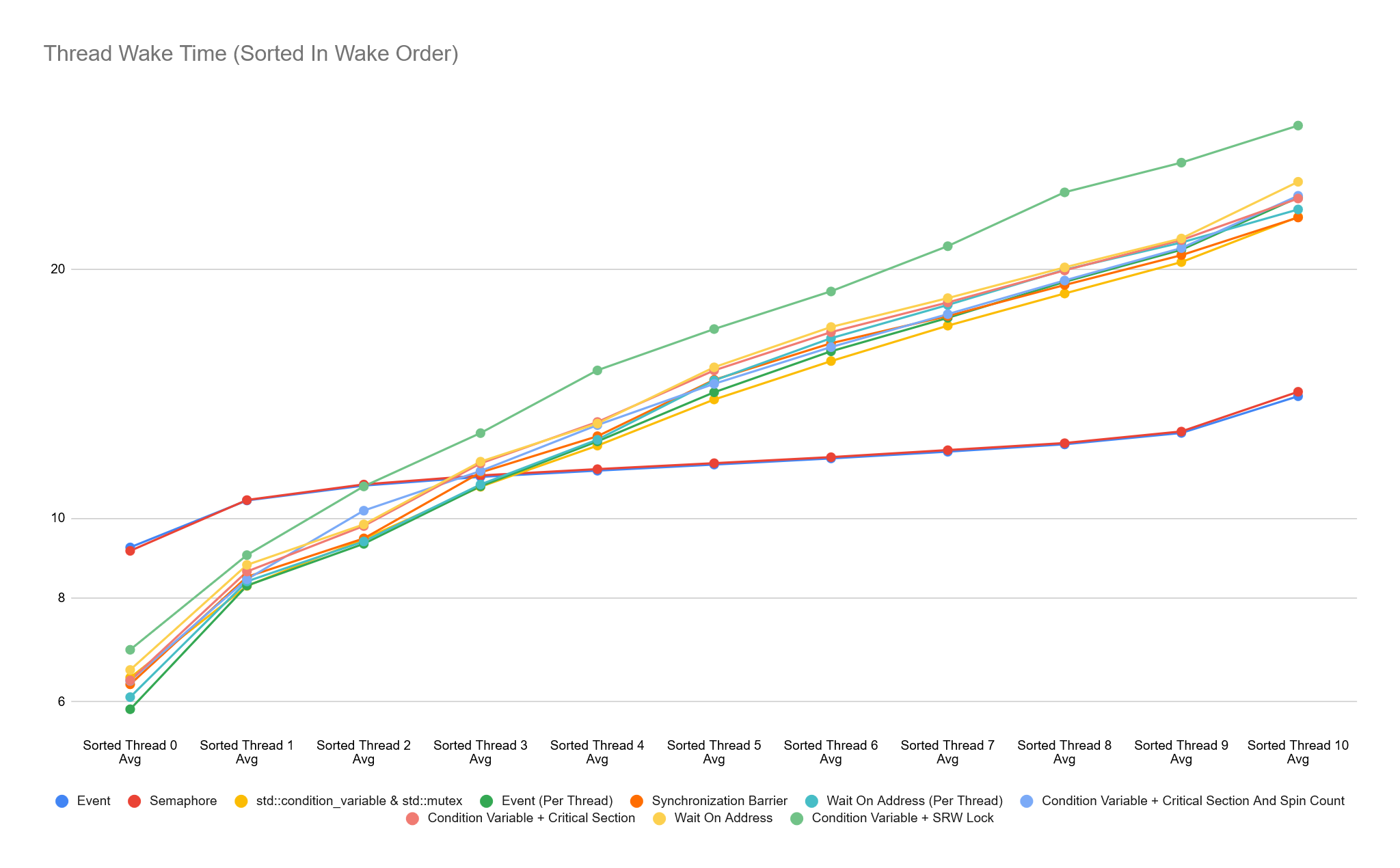
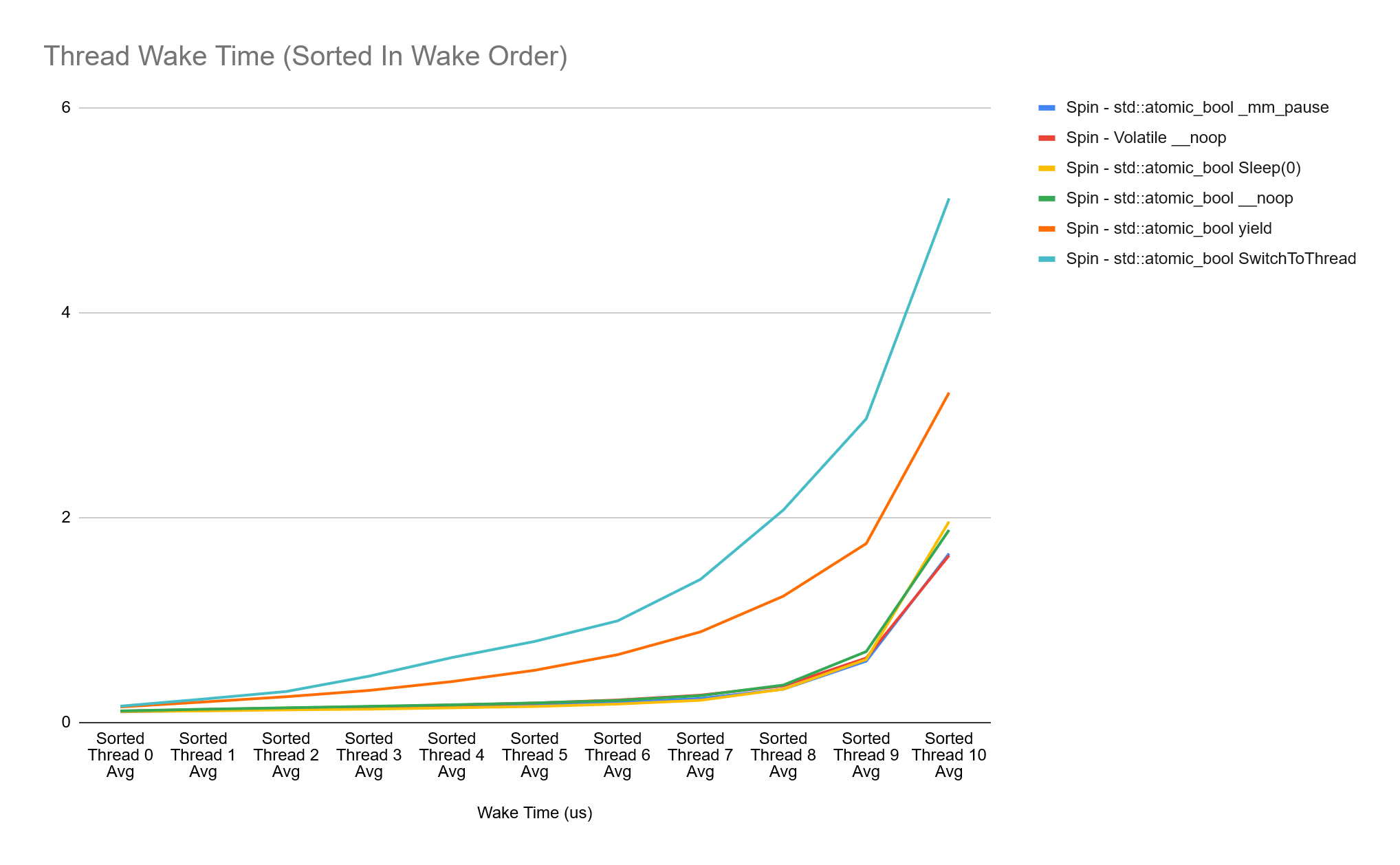
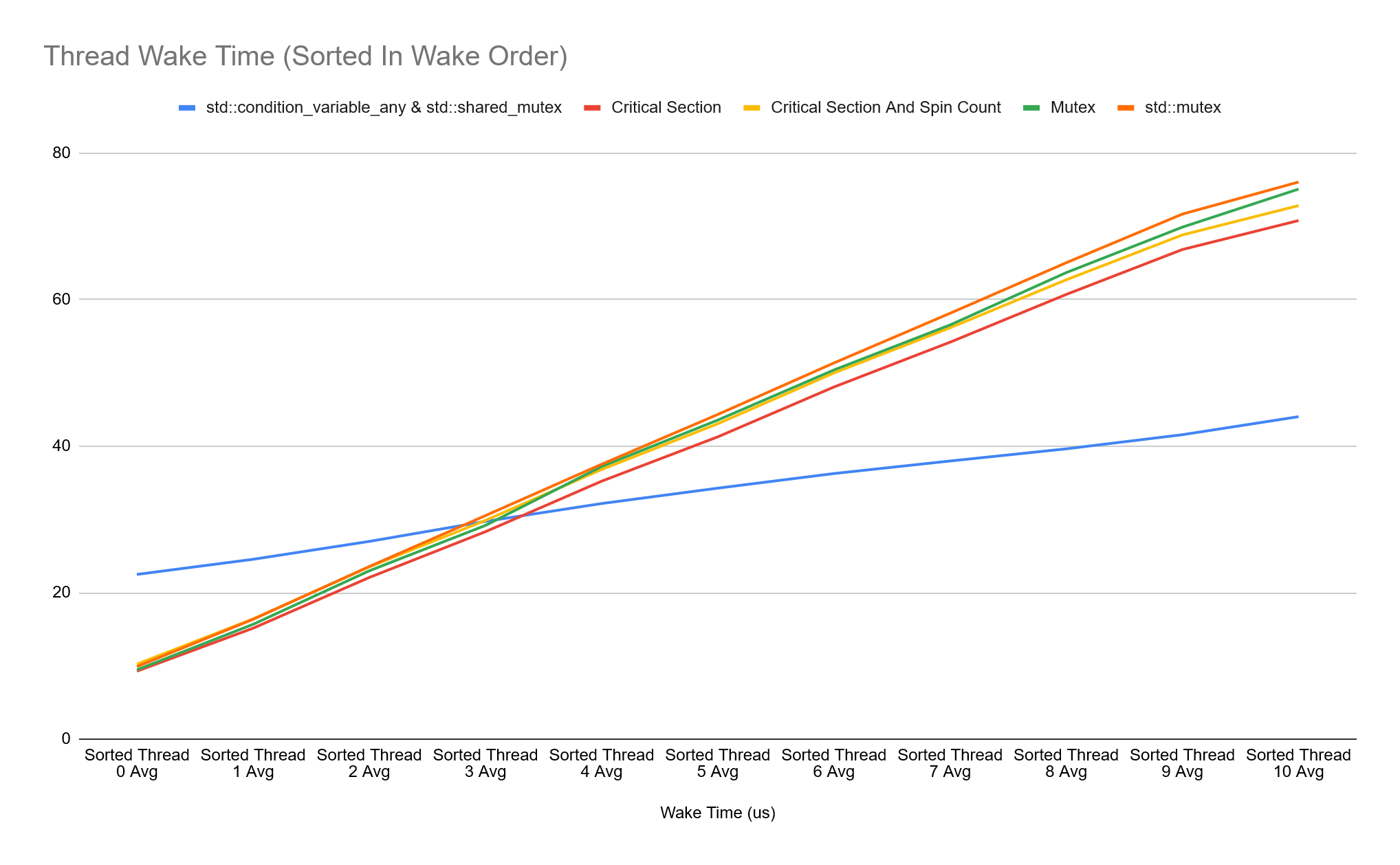
There is a lot of overlapping data in the charts above, so it can be difficult to see in an image. The standout here though is that the Event and Semaphore types have the most consistent wake time across all threads, while other sync times vary a lot more between the first and last thread woken. The outlier is the Condition Variable + SRW Lock, this varies from 6us all the way to 30us. What’s also interesting is that all sync types other than Event and Semaphore are faster at waking the first 3 threads, but then the cost increases significantly.
So the results above got me thinking… Instead of having an Event per thread or a single Event for all threads, could a hybrid approach give some benefits? E.g, having an Event object for x number of threads. We’ve already got two variants of the Event type, a single one which triggers all threads and another setup where we have 11 Event types for each thread which we trigger in order. This may not even have to just extend to the Event primitive, could any of the sync types benefit from a hybrid approach?
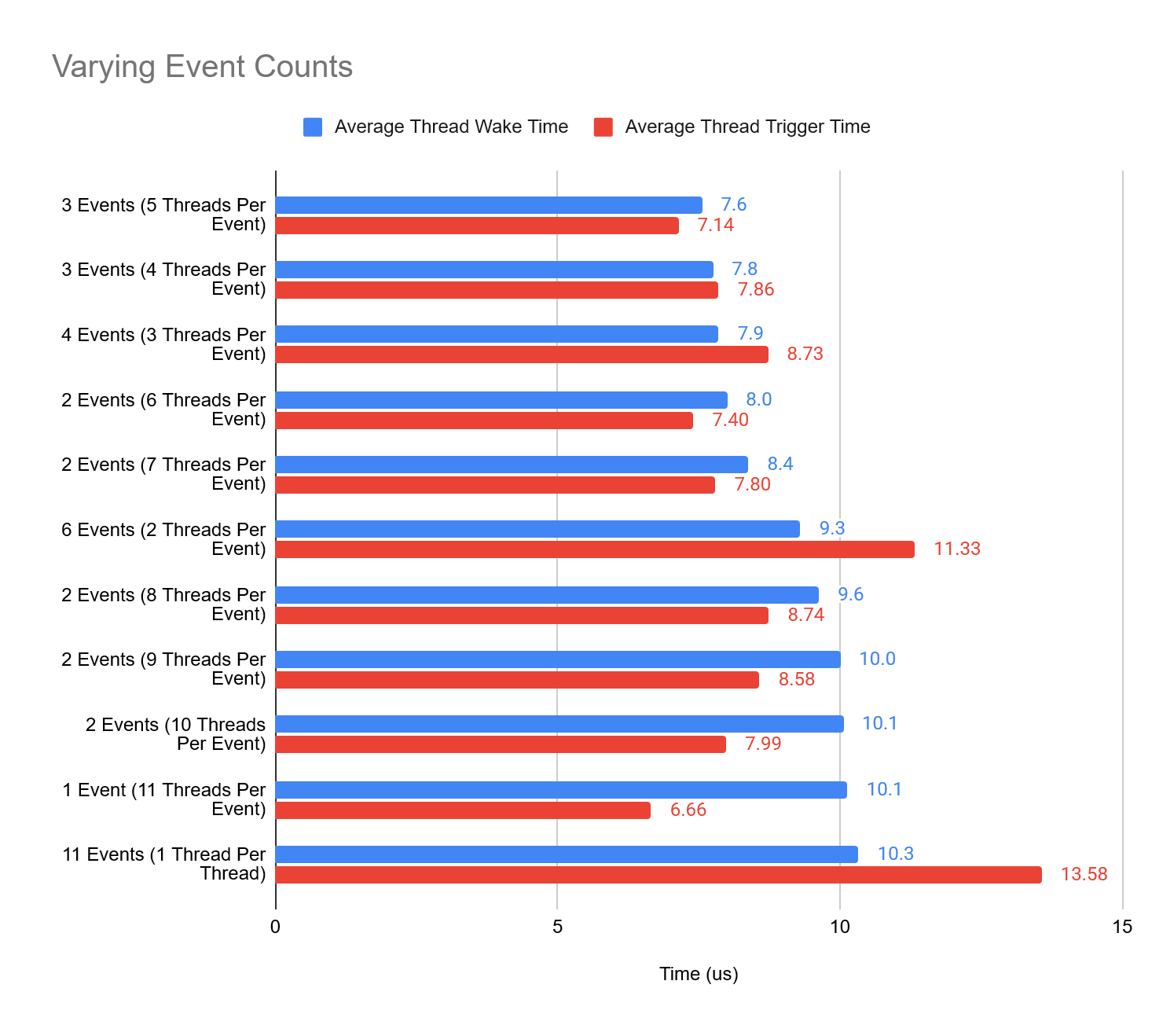
The data above shows that we can increase the average thread waking performance from having a single event trigger all threads with a small increase in trigger time. The sweet spot here, where we had 11 worker threads in total to have 3 event types with the first two triggering 5 threads each, and the last triggering just a single thread.
Next Steps
To some extent, I feel like I’ve only scratched the surface here and there is still a lot more to explore surrounding this such as the following:
- Exploring how
timeBeginPeriod/timeEndPeriodaffects performance. - What is actually happening under the hood of each sync time and how that impacts the performance overhead. Almost all waiting threads appear to end up waiting in a syscall to
NtWaitForAlertByThreadIdbut there is a clear difference in trigger and waking performance occuring despite this. - We explored how splitting the Event type resulted in better performance, could this be done for other sync types for better performance?
- How do these tests change on different hardware setups? I’m particularly interested in how the thread waking performance would work on say a 192 logical processor Thread Ripper, the overhead of unlocking such a huge number of threads must be particularly slow, but perhaps you wouldn’t write a job system which could equally spread over such a huge number of threads.
- How would these tests compare under Linux and using some of the Linux native synchronisation types?
- I plan to clean up and share the source code I have written for these tests in the future.
Leave a Reply